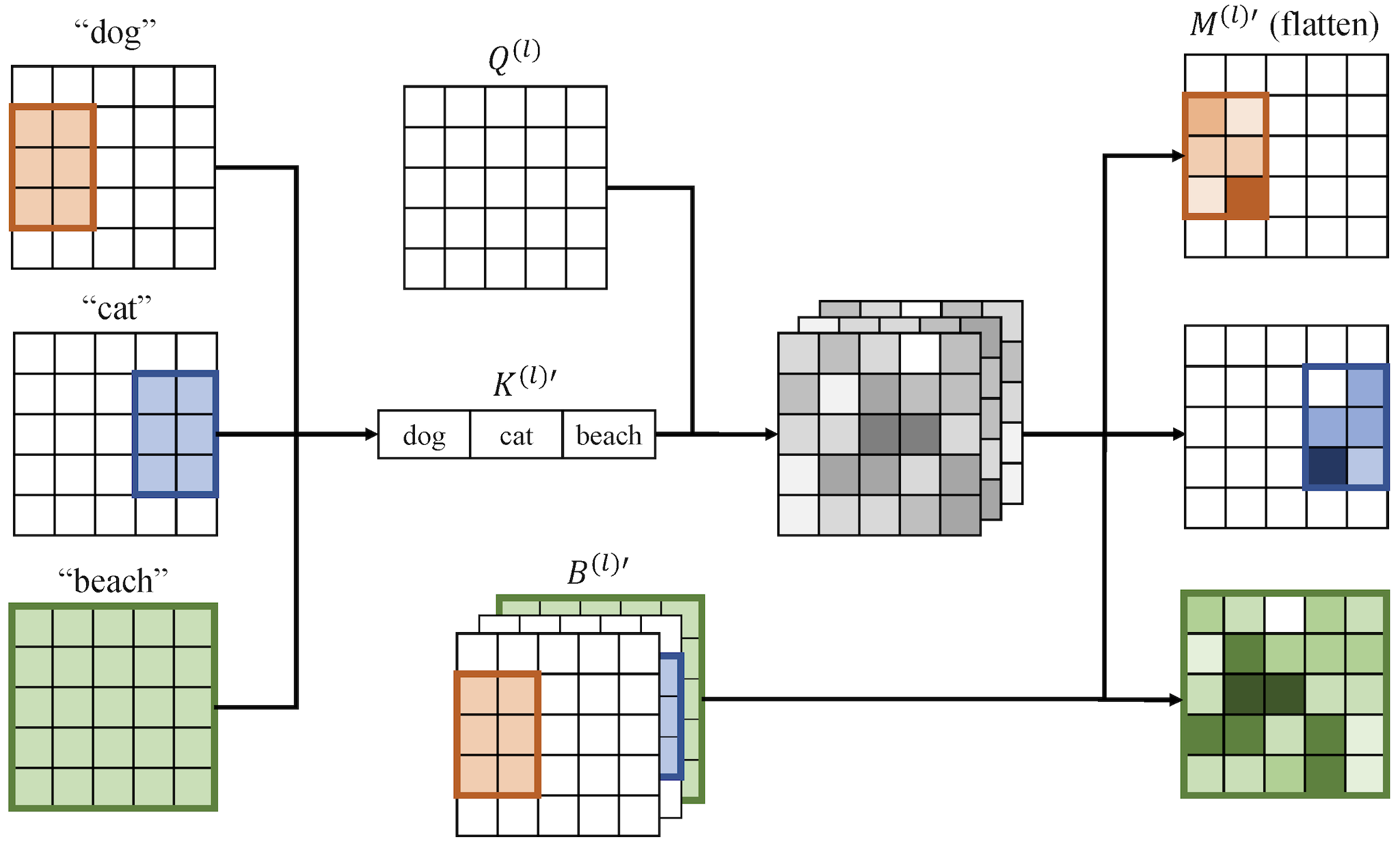
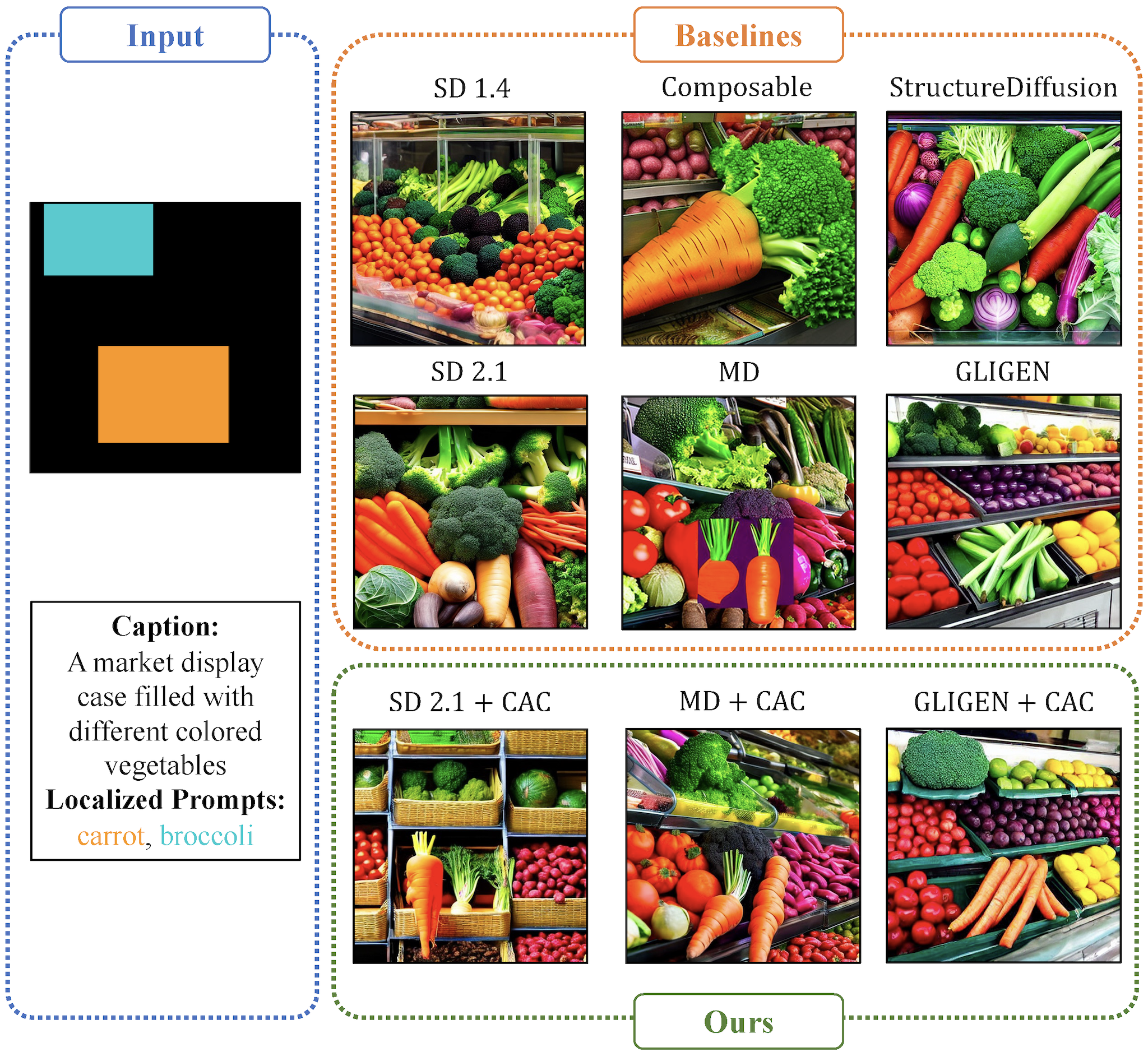
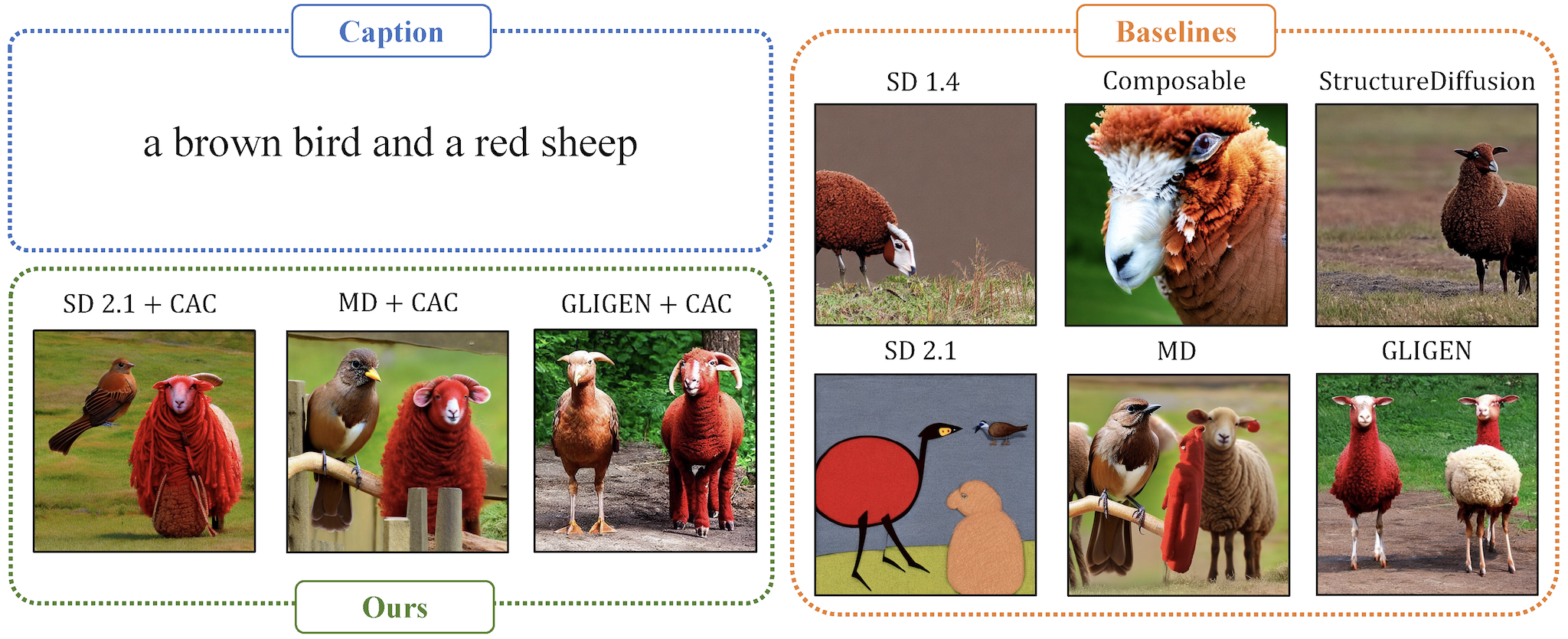
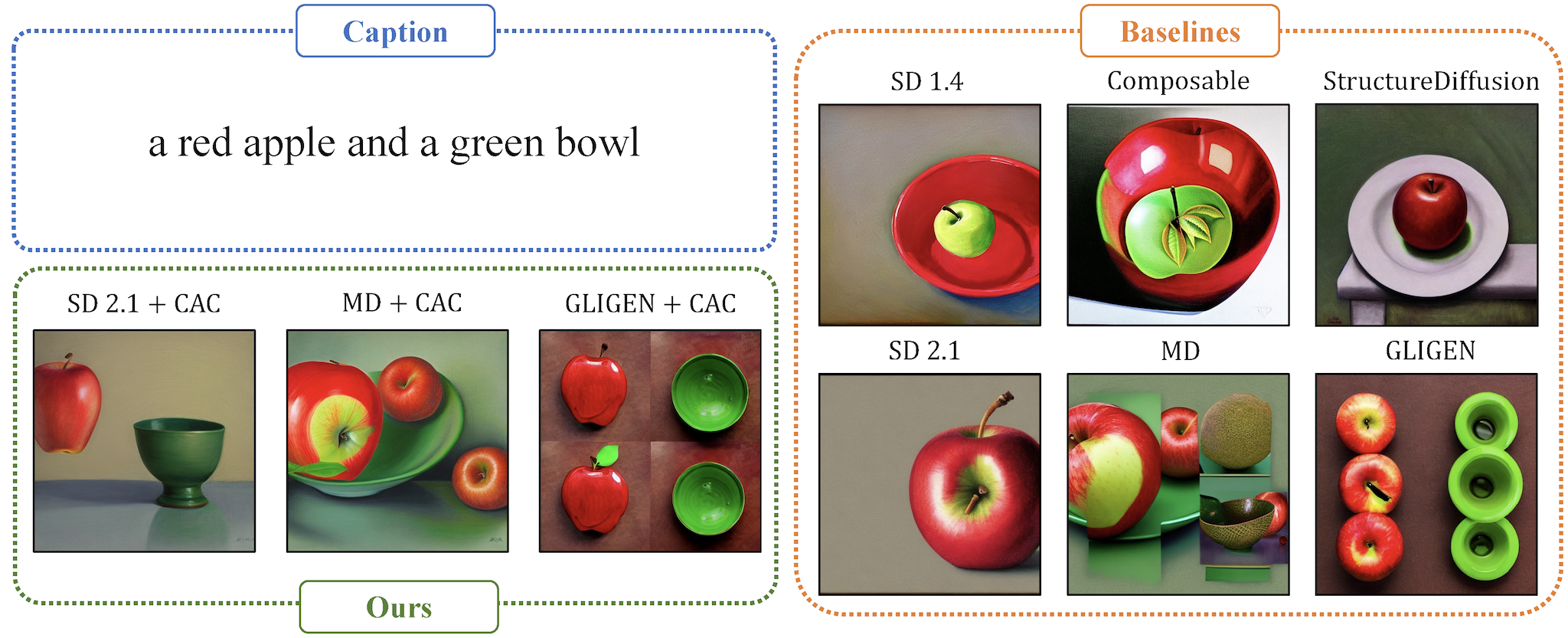
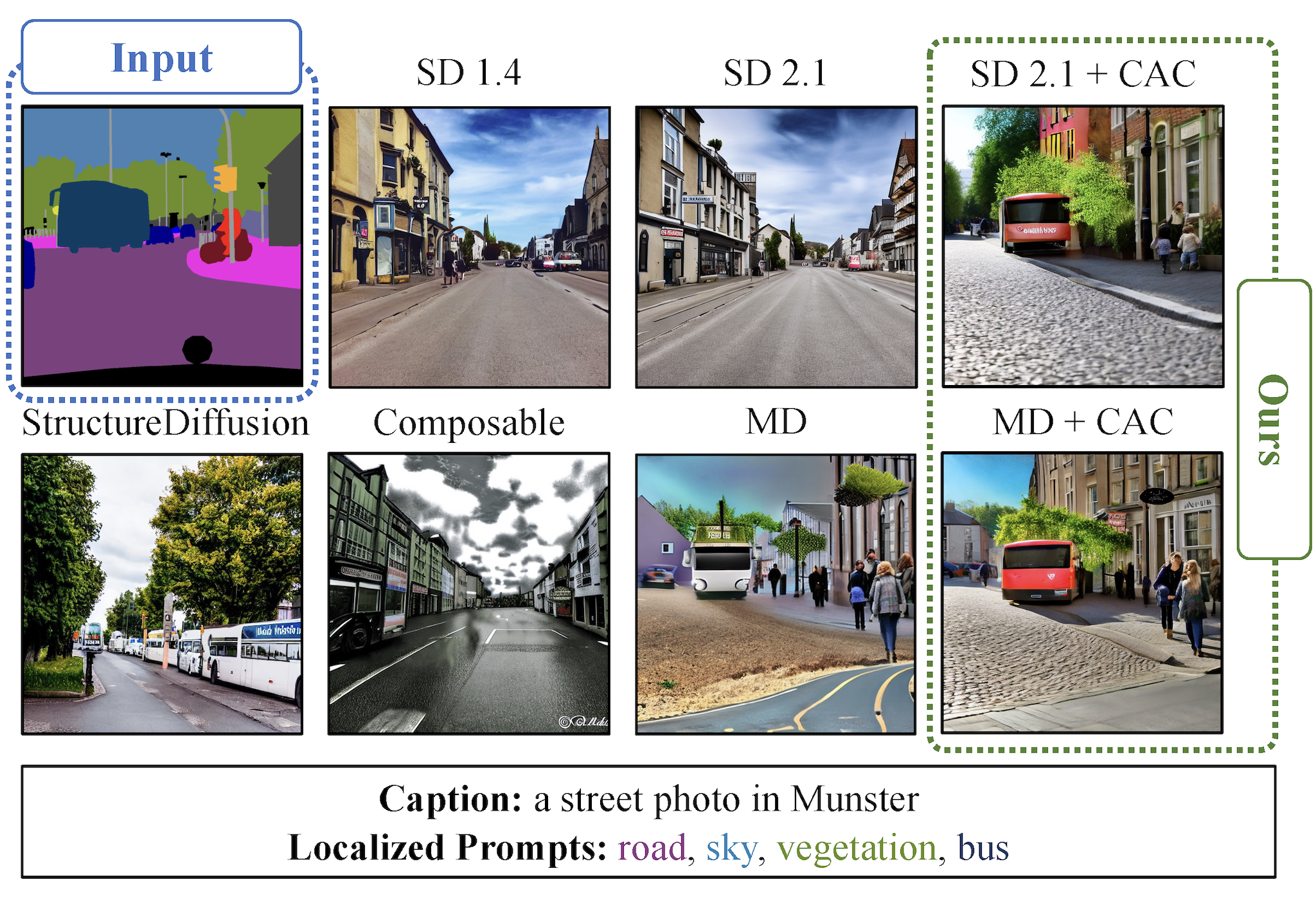
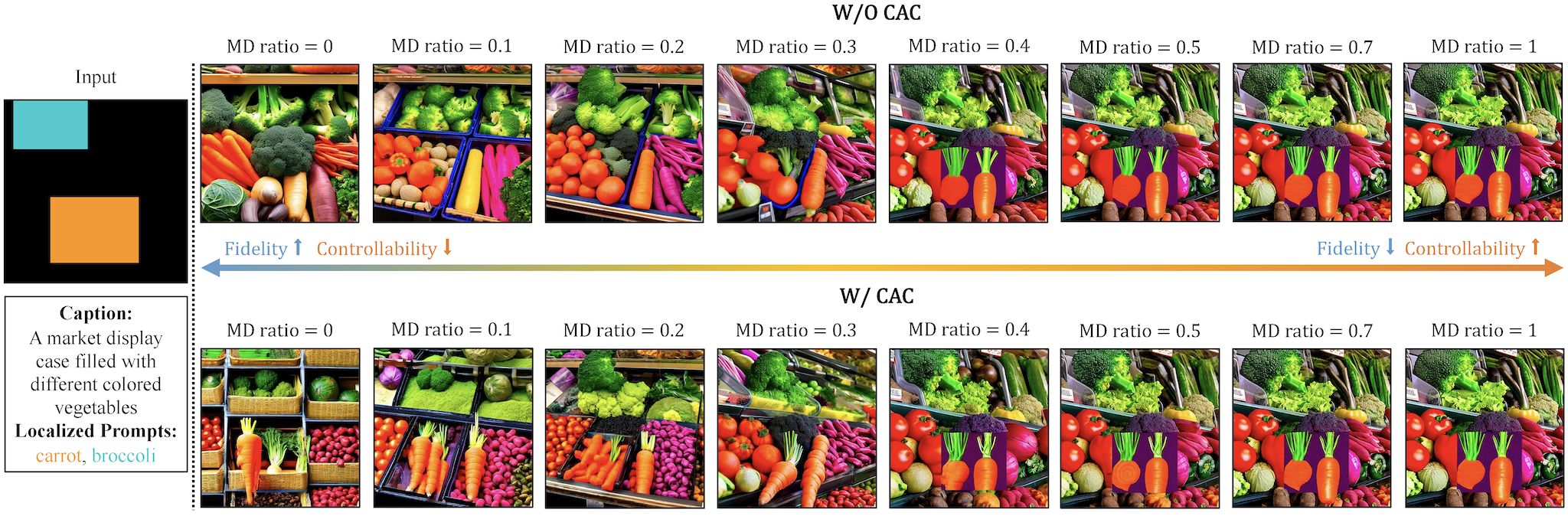
Despite the tremendous success in text-to-image generative models, localized text-to-image generation (that is, generating objects or features at specific locations in an image while maintaining a consistent overall generation) still requires either explicit training or substantial additional inference time. In this work, we show that localized generation can be achieved by simply controlling cross attention maps during inference. With no additional training, model architecture modification or inference time, our proposed cross attention control (CAC) provides new open-vocabulary localization abilities to standard text-to-image models. CAC also enhances models that are already trained for localized generation when deployed at inference time. Furthermore, to assess localized text-to-image generation performance automatically, we develop a standardized suite of evaluations using large pretrained recognition models. Our experiments show that CAC improves localized generation performance with various types of location information ranging from bounding boxes to semantic segmentation maps, and enhances the compositional capability of state-of-the-art text-to-image generative models.




@article{he2023localized,
title={Localized Text-to-Image Generation for Free via Cross Attention Control},
author={Yutong He and Ruslan Salakhutdinov and J. Zico Kolter},
journal={arXiv preprint arXiv:2306.14636},
year={2023}
}